Цикл в таблице данных sql
- 03/15/2017
- Чтение занимает 2 мин
В этой статье
Применимо к:Applies to: SQL ServerSQL Server (все поддерживаемые версии) SQL ServerSQL Server (all supported versions) База данных SQL AzureAzure SQL DatabaseБаза данных SQL AzureAzure SQL Database Управляемый экземпляр SQL AzureAzure SQL Managed InstanceУправляемый экземпляр SQL AzureAzure SQL Managed Instance Azure Synapse AnalyticsAzure Synapse AnalyticsAzure Synapse AnalyticsAzure Synapse Analytics Параллельное хранилище данныхParallel Data WarehouseПараллельное хранилище данныхParallel Data WarehouseПрименимо к:Applies to: SQL ServerSQL Server (все поддерживаемые версии) SQL ServerSQL Server (all supported versions) База данных SQL AzureAzure SQL DatabaseБаза данных SQL AzureAzure SQL Database Управляемый экземпляр SQL AzureAzure SQL Managed InstanceУправляемый экземпляр SQL AzureAzure SQL Managed Instance Azure Synapse AnalyticsAzure Synapse AnalyticsAzure Synapse AnalyticsAzure Synapse Analytics Параллельное хранилище данныхParallel Data WarehouseПараллельное хранилище данныхParallel Data Warehouse
Ставит условие повторного выполнения SQL-инструкции или блока инструкций.Sets a condition for the repeated execution of an SQL statement or statement block. Эти инструкции вызываются в цикле, пока указанное условие истинно.The statements are executed repeatedly as long as the specified condition is true. Вызовами инструкций в цикле WHILE можно контролировать из цикла с помощью ключевых слов BREAK и CONTINUE.The execution of statements in the WHILE loop can be controlled from inside the loop with the BREAK and CONTINUE keywords.
Синтаксические обозначения в Transact-SQLTransact-SQL Syntax Conventions
СинтаксисSyntax
— Syntax for SQL Server and Azure SQL Database
WHILE Boolean_expression
{ sql_statement | statement_block | BREAK | CONTINUE }
— Syntax for Azure Azure Synapse Analytics and Parallel Data Warehouse
WHILE Boolean_expression
{ sql_statement | statement_block | BREAK }
АргументыArguments
Boolean_expressionBoolean_expression
Выражение, возвращающее значение TRUE или FALSE.Is an expression that returns TRUE or FALSE. Если логическое выражение содержит инструкцию SELECT, инструкция SELECT должна быть заключена в скобки.If the Boolean expression contains a SELECT statement, the SELECT statement must be enclosed in parentheses.
{sql_statement | statement_block}{sql_statement | statement_block}
Любая инструкция или группа инструкций Transact-SQLTransact-SQL, определенная в виде блока инструкций.Is any Transact-SQLTransact-SQL statement or statement grouping as defined with a statement block. Для определения блока инструкций используйте ключевые слова потока управления BEGIN и END.To define a statement block, use the control-of-flow keywords BEGIN and END.
BREAKBREAK
Приводит к выходу из ближайшего цикла WHILE.Causes an exit from the innermost WHILE loop. Вызываются инструкции, следующие за ключевым словом END, обозначающим конец цикла.Any statements that appear after the END keyword, marking the end of the loop, are executed.
CONTINUECONTINUE
Выполняет цикл WHILE для перезагрузки, не учитывая все инструкции, следующие после ключевого слова CONTINUE.Causes the WHILE loop to restart, ignoring any statements after the CONTINUE keyword.
Если вложенными являются два цикла WHILE или более, внутренний оператор BREAK существует до следующего внешнего цикла.If two or more WHILE loops are nested, the inner BREAK exits to the next outermost loop. Все инструкции после окончания внутреннего цикла выполняются в первую очередь, а затем перезапускается следующий внешний цикл.All the statements after the end of the inner loop run first, and then the next outermost loop restarts.
ПримерыExamples
A.A. Использование ключевых слов BREAK и CONTINUE внутри вложенных конструкций IF…ELSE и WHILEUsing BREAK and CONTINUE with nested IF…ELSE and WHILE
В следующем примере в случае, если средняя цена продуктов из списка меньше чем $300, цикл WHILE удваивает цены, а затем выбирает максимальную.In the following example, if the average list price of a product is less than $300, the WHILE loop doubles the prices and then selects the maximum price. В том случае, если максимальная цена меньше или равна $500, цикл WHILE повторяется и снова удваивает цены.If the maximum price is less than or equal to $500, the WHILE loop restarts and doubles the prices again. Этот цикл продолжает удваивать цены до тех пор, пока максимальная цена не будет больше чем $500, затем выполнение цикла WHILE прекращается, о чем выводится соответствующее сообщение.This loop continues doubling the prices until the maximum price is greater than $500, and then exits the WHILE loop and prints a message.
USE AdventureWorks2012;
GO
WHILE (SELECT AVG(ListPrice) FROM Production.Product) < $300
BEGIN
UPDATE Production.Product
SET ListPrice = ListPrice * 2
SELECT MAX(ListPrice) FROM Production.Product
IF (SELECT MAX(ListPrice) FROM Production.Product) > $500
BREAK
ELSE
CONTINUE
END
PRINT ‘Too much for the market to bear’;
Б.B. Применение инструкции WHILE в курсореUsing WHILE in a cursor
В следующем примере используется переменная @@FETCH_STATUS для управления действиями курсора в цикле WHILE.The following example uses @@FETCH_STATUS to control cursor activities in a WHILE loop.
DECLARE @EmployeeID as NVARCHAR(256)
DECLARE @Title as NVARCHAR(50)
DECLARE Employee_Cursor CURSOR FOR
SELECT LoginID, JobTitle
FROM AdventureWorks2012.HumanResources.Employee
WHERE JobTitle = ‘Marketing Specialist’;
OPEN Employee_Cursor;
FETCH NEXT FROM Employee_Cursor INTO @EmployeeID, @Title;
WHILE @@FETCH_STATUS = 0
BEGIN
Print ‘ ‘ + @EmployeeID + ‘ ‘+ @Title
FETCH NEXT FROM Employee_Cursor INTO @EmployeeID, @Title;
END;
CLOSE Employee_Cursor;
DEALLOCATE Employee_Cursor;
GO
Примеры: Azure Synapse AnalyticsAzure Synapse Analytics и Параллельное хранилище данныхParallel Data WarehouseExamples: Azure Synapse AnalyticsAzure Synapse Analytics and Параллельное хранилище данныхParallel Data Warehouse
В. Простой цикл WhileC: Simple While Loop
В следующем примере в случае, если средняя цена продуктов из списка меньше чем $300, цикл WHILE удваивает цены, а затем выбирает максимальную.In the following example, if the average list price of a product is less than $300, the WHILE loop doubles the prices and then selects the maximum price. В том случае, если максимальная цена меньше или равна $500, цикл WHILE повторяется и снова удваивает цены.If the maximum price is less than or equal to $500, the WHILE loop restarts and doubles the prices again. Этот цикл продолжает удваивать цены до тех пор, пока максимальная цена не будет больше, чем $500, после чего выполнение цикла WHILE прекращается.This loop continues doubling the prices until the maximum price is greater than $500, and then exits the WHILE loop.
— Uses AdventureWorks
WHILE ( SELECT AVG(ListPrice) FROM dbo.DimProduct) < $300
BEGIN
UPDATE dbo.DimProduct
SET ListPrice = ListPrice * 2;
SELECT MAX ( ListPrice) FROM dbo.DimProduct
IF ( SELECT MAX (ListPrice) FROM dbo.DimProduct) > $500
BREAK;
END
См. такжеSee Also
ALTER TRIGGER (Transact-SQL) ALTER TRIGGER (Transact-SQL)
Язык управления потоком (Transact-SQL) Control-of-Flow Language (Transact-SQL)
CREATE TRIGGER (Transact-SQL) CREATE TRIGGER (Transact-SQL)
Курсоры (Transact-SQL) Cursors (Transact-SQL)
SELECT (Transact-SQL)SELECT (Transact-SQL)
Источник
Сегодня будем рассматривать очень много чего интересного, например как запустить уже созданную процедуру, которая принимает параметры, массово, т.е. не только со статическим параметрами, а с параметрами, которые будут меняться, например, на основе какой-нибудь таблицы, как обычная функция, и в этом нам помогут как раз курсоры и циклы, и как это все реализовать сейчас будем смотреть.
Как Вы поняли, курсоры и циклы мы будем рассматривать применимо к конкретной задачи. А какой задачи, сейчас расскажу.
Существует процедура, которая выполняет какие-то действия, которые не может выполнить обычная функция SQL например, расчеты и insert на основе этих расчетов. И Вы ее запускаете, например вот так:
EXEC test_PROCEDURE par1, par2
Другими словами Вы запускаете ее только с теми параметрами, которые были указаны, но если Вам необходимо запустить данную процедуру скажем 100, 200 или еще более раз, то согласитесь это не очень удобно, т.е. долго. Было бы намного проще, если бы мы взяли и запускали процедуру как обычную функцию в запросе select, например:
SELECT my_fun(id) FROM test_table
Другими словами функция отработает на каждую запись таблицы test_table, но как Вы знаете процедуру так использовать нельзя. Но существует способ, который поможет нам осуществить задуманное, точнее даже два способа первый это с использованием курсора и цикла и второй это просто с использованием цикла, но уже без курсора. Оба варианта подразумевают, что мы будем создавать дополнительную процедуру, которую в дальнейшем мы будем запускать.
Примечание! Все примеры будем писать в СУБД MS SQL Server 2008, используя Management Studio. Также все нижеперечисленные действия требуют определённых знаний языка SQL, а точнее Transact-SQL. Начинающим могу посоветовать посмотреть мой видеокурс по T-SQL, на котором рассматриваются все базовые конструкции.
И так приступим, и перед тем как писать процедуру, давайте рассмотрим исходные данные нашего примера.
Допустим, есть таблица test_table
CREATE TABLE [dbo].[test_table](
[number] [numeric](18, 0) NULL,
[pole1] [varchar](50) NULL,
[pole2] [varchar](50) NULL
) ON [PRIMARY]
GO
В нее необходимо вставлять данные, на основе каких-то расчетов, которые будет выполнять процедура my_proc_test, в данном случае она просто вставляет данные, но на практике Вы можете использовать свою процедуру, которая может выполнять много расчетов, поэтому в нашем случае именно эта процедура не важна, она всего лишь для примера. Ну, давайте создадим ее:
CREATE PROCEDURE [dbo].[my_proc_test]
(@number numeric, @pole1 varchar(50), @pole2 varchar(50))
AS
BEGIN
INSERT INTO dbo.test_table (number, pole1, pole2)
VALUES (@number, @pole1, @pole2)
END
GO
Она просто принимает три параметра и вставляет их в таблицу.
И допустим эту процедуру, нам нужно запустить столько раз, сколько строк в какой-нибудь таблице или представлении (VIEWS) , другими словами запустить ее массово для каждой строки источника.
И для примера создадим такой источник, у нас это будет простая таблица test_table_vrem, а у Вас это может быть, как я уже сказал свой источник, например временная таблица или представление:
CREATE TABLE [dbo].[test_table_vrem](
[number] [numeric](18, 0) NULL,
[pole1] [varchar](50) NULL,
[pole2] [varchar](50) NULL
) ON [PRIMARY]
GO
Заполним ее тестовыми данными:
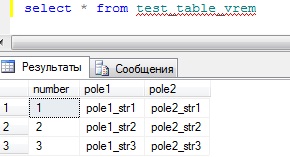

И теперь нашу процедуру необходимо запустить для каждой строки, т.е. три раза с разными параметрами. Как Вы понимаете значения этих полей и есть наши параметры, другими словами, если бы мы запускали нашу процедуру вручную, это выглядело вот так:
exec my_proc_test 1, ‘pole1_str1’, ‘pole2_str1’
И так еще три раза, с соответствующими параметрами.
Но нам так не охота, поэтому мы напишем еще одну дополнительную процедуру, которая и будет запускать нашу основную процедуру столько раз, сколько нам нужно.
Первый вариант.
Используем курсор и цикл в процедуре
Перейдем сразу к делу и напишем процедуру (my_proc_test_all), код я как всегда прокомментировал:
CREATE PROCEDURE [dbo].[my_proc_test_all]
AS
–объявляем переменные
DECLARE @number bigint
DECLARE @pole1 varchar(50)
DECLARE @pole2 varchar(50)
–объявляем курсор
DECLARE my_cur CURSOR FOR
SELECT number, pole1, pole2
FROM test_table_vrem
–открываем курсор
OPEN my_cur
–считываем данные первой строки в наши переменные
FETCH NEXT FROM my_cur INTO @number, @pole1, @pole2
–если данные в курсоре есть, то заходим в цикл
–и крутимся там до тех пор, пока не закончатся строки в курсоре
WHILE @@FETCH_STATUS = 0
BEGIN
–на каждую итерацию цикла запускаем нашу основную процедуру с нужными параметрами
exec dbo.my_proc_test @number, @pole1, @pole2
–считываем следующую строку курсора
FETCH NEXT FROM my_cur INTO @number, @pole1, @pole2
END
–закрываем курсор
CLOSE my_cur
DEALLOCATE my_cur
GO
И теперь осталось нам ее вызвать и проверить результат:
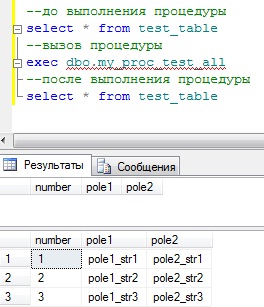
Код:
–до выполнения процедуры
SELECT * FROM test_table
–вызов процедуры
EXEC dbo.my_proc_test_all
–после выполнения процедуры
SELECT * FROM test_table
Как видите, все у нас отработало как надо, другими словами процедура my_proc_test сработала все три раза, а мы всего лишь один раз запустили дополнительную процедуру.
Второй вариант.
Используем только цикл в процедуре
Сразу скажу, что здесь требуется нумерация строк во временной таблице, т.е. каждая строка должна быть пронумерована, например 1, 2, 3 таким полем у нас во временной таблице служит number.
Пишем процедуру my_proc_test_all_v2
CREATE PROCEDURE [dbo].[my_proc_test_all_v2]
AS
–объявляем переменные
DECLARE @number bigint
DECLARE @pole1 varchar(50)
DECLARE @pole2 varchar(50)
DECLARE @cnt int
DECLARE @i int
–узнаем количество строк во временной таблице
SELECT @cnt=count(*)
FROM test_table_vrem
–задаем начальное значение идентификатора
SET @i=1
WHILE @cnt >= @i
BEGIN
–присваиваем значения нашим параметрам
SELECT @number=number, @pole1= pole1, @pole2=pole2
FROM test_table_vrem
WHERE number = @I
–на каждую итерацию цикла запускаем нашу основную процедуру с нужными параметрами
EXEC dbo.my_proc_test @number, @pole1, @pole2
–увеличиваем шаг
set @i= @i+1
END
GO
И проверяем результат, но для начала очистим нашу таблицу, так как мы же ее только что уже заполнили по средствам процедуры my_proc_test_all:
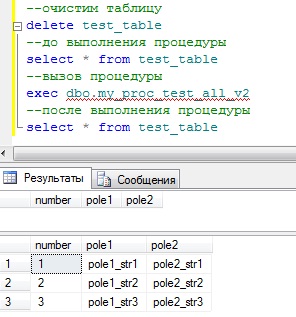
–очистим таблицу
DELETE test_table
–до выполнения процедуры
SELECT * FROM test_table
–вызов процедуры
EXEC dbo.my_proc_test_all_v2
–после выполнения процедуры
SELECT * FROM test_table
Как и ожидалось результат такой же, но уже без использования курсоров. Какой вариант использовать решать Вам, первый вариант хорош, тем, что в принципе не нужна нумерация, но как Вы знаете, курсоры работают достаточно долго, если строк в курсоре будет много, а второй вариант хорош тем, что отработает, как мне кажется быстрей, опять же таки, если строк будет много, но нужна нумерация, лично мне нравится вариант с курсором, а вообще решать Вам может Вы сами придумаете что-то более удобное, я всего лишь показал основы того, как можно реализовать поставленную задачу. Удачи!
Заметка! Если Вас интересует SQL и T-SQL, рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать с использованием языка T-SQL в Microsoft SQL Server.
Источник
| Бесплатный Видеокурс по PHP! Пример создания реального PHP-сайта с нуля! Подробнее |

Сегодня узнаем, как работать с циклами, т.е. выполнять один и тот же запрос несколько раз. В MySQL для работы с циклами применяются
операторы WHILE, REPEAT и LOOP.
Оператор цикла WHILE
Сначала синтаксис:
WHILE условие DO
запрос
END WHILE
Запрос будет выполняться до тех пор, пока условие истинно. Давайте посмотрим на примере, как это работает. Предположим, мы хотим знать названия,
авторов и количество книг, которые поступили в различные поставки. Интересующая нас информация хранится в двух таблицах – Журнал Поставок
(magazine_incoming) и Товар (products). Давайте напишим интересующий нас запрос:
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product;
А что, если нам необходимо, чтобы результат выводился не в одной таблице, а по каждой поставке отдельно? Конечно, можно написать 3 разных
запроса, добавив в каждый еще одно условие:
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=1;
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=2;
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=3;
Но гораздо короче сделать это можно с помощью цикла WHILE:
DECLARE i INT DEFAULT 3;
WHILE i>0 DO
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=i;
SET i=i-1;
END WHILE;
Т.е. мы ввели переменную i, по умолчанию равную 3, сервер выполнит запрос с id поставки равным 3, затем уменьшит i на единицу (SET i=i-1),
убедится, что новое значение переменной i положительно (i>0) и снова выполнит запрос, но уже с новым значением id поставки равным 2.
Так будет происходить, пока переменная i не получит значение 0, условие станет ложным, и цикл закончит свою работу.
Чтобы убедиться в работоспособности цикла создадим хранимую процедуру books и поместим в нее цикл:
DELIMITER //
CREATE PROCEDURE books ()
begin
DECLARE i INT DEFAULT 3;
WHILE i>0 DO
SELECT magazine_incoming.id_incoming, products.name, products.author,
magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product
AND magazine_incoming.id_incoming=i;
SET i=i-1;
END WHILE;
end
//
Теперь вызовем процедуру:
CALL books ()//
Теперь у нас 3 отдельные таблицы (по каждой поставке). Согласитесь, что код с циклом гораздо короче трех отдельных запросов. Но в нашей
процедуре есть одно неудобство, мы объявили количество выводимых таблиц значением по умолчанию (DEFAULT 3), и нам придется с каждой
новой поставкой менять это значение, а значит код процедуры. Гораздо удобнее сделать это число входным параметром. Давайте перепишем
нашу процедуру, добавив входной параметр num, и, учитывая, что он не должен быть равен 0:
CREATE PROCEDURE books (IN num INT)
begin
DECLARE i INT DEFAULT 0;
IF (num>0) THEN
WHILE i
Убедитесь, что с другими параметрами, мы по-прежнему получаем таблицы по каждой поставке. У нашего цикла есть еще один недостаток – если случайно задать
слишком большое входное значение, то мы получим псевдобесконечный цикл, который загрузит сервер бесполезной работой. Такие ситуации предотвращаются
с помощью снабжения цикла меткой и использования оператора LEAVE, обозначающего досрочный выход из цикла.
CREATE PROCEDURE books (IN num INT)
begin
DECLARE i INT DEFAULT 0;
IF (num>0) THEN
wet : WHILE i 10) THEN LEAVE wet;
ENF IF;
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=i;
SET i=i+1;
END WHILE wet;
ELSE
SELECT ‘Задайте правильный параметр’;
END IF;
end
//
Итак, мы снабдили наш цикл меткой wet вначале (wet:) и в конце, а также добавили еще одно условие – если входной параметр больше 10
(число 10 взято произвольно), то цикл с меткой wet следует закончить (IF (i>10) THEN LEAVE wet). Таким образом, если мы случайно вызовем
процедуру с большим значением num, наш цикл прервется после 10 итераций (итерация – один проход цикла).
Циклы в MySQL, так же как и операторы ветвления, на практике в web-приложениях почти не используются. Поэтому для двух других видов циклов
приведем лишь синтаксис и отличия. Вряд ли вам доведется их использовать, но знать об их существовании все-таки надо.
Оператор цикла REPEAT
Условие цикла проверяется не в начале, как в цикле WHILE, а в конце, т.е. хотя бы один раз, но цикл выполняется. Сам же цикл выполняется, пока
условие ложно. Синтаксис следующий:
REPEAT
запрос
UNTIL условие
END REPEAT
Оператор цикла LOOP
Этот цикл вообще не имеет условий, поэтому обязательно должен иметь оператор LEAVE. Синтаксис следующий:
LOOP
запрос
END LOOP
На этом мы заканчиваем уроки посвященные SQL. Конечно, мы рассмотрели не все возможности этого языка запросов, но в реальной жизни вам вряд ли
придется столкнуться даже с тем, что вы уже знаете.
Напомню, на реальных сайтах, вы обычно вводите информацию в какие-нибудь html-формы, затем сценарий на каком-либо языке (php, java…) извлекает
эти данные из формы и заносит их в БД. При необходимости происходит обратный процесс, т.е. данные извлекаются из БД и выводятся на страницы
сайта. Оба процесса происходят посредством SQL-запросов. HTML вы знаете, с базами данных разобрались, SQL-запросы писать научились, осталось
изучить PHP, чтобы ваши сайты превратились в полноправные web-приложения. Это и есть ваш следующий шаг. До встречи в уроках PHP.
Предыдущий урок
Вернуться в раздел
Видеоуроки php + mysql
- Видеокурс “PHP и MySQL с Нуля до Гуру 2.0”
- Как создаётся движок сайта на PHP и MySQL
Если этот сайт оказался вам полезен, пожалуйста, посмотрите другие наши статьи и разделы.
| Код кнопки: |
Теперь нажмите кнопку, что бы не забыть адрес и вернуться к нам снова.
Источник
Периодически возникает задача поиска связанных данных по набору ключей, пока не наберем нужное суммарное количество записей.
Наиболее «жизненный» пример — вывести 20 самых старых задач, числящихся на списке сотрудников (например, в рамках одного подразделения). Для различных управленческих «дашбордов» с краткими выжимками по участкам работы похожая тема требуется достаточно часто.
В статье рассмотрим реализацию на PostgreSQL «наивного» варианта решения такой задачи, «поумнее» и совсем сложный алгоритм «цикла» на SQL с условием выхода от найденных данных, который может быть полезен как для общего развития, так и для применения в других похожих случаях.
Возьмем тестовый набор данных из предыдущей статьи. Чтобы выводимые записи не «скакали» от раза к разу при совпадении сортируемых значений, расширим предметный индекс добавлением первичного ключа. Заодно это сразу придаст ему уникальность, и гарантирует нам однозначность порядка сортировки:
CREATE INDEX ON task(owner_id, task_date, id);
— а старый – удалим
DROP INDEX task_owner_id_task_date_idx;
Как слышится, так и пишется
Сначала набросаем самый простой вариант запроса, передавая ID исполнителей массивом в качестве входного параметра:
SELECT
*
FROM
task
WHERE
owner_id = ANY(‘{1,2,4,8,16,32,64,128,256,512}’::integer[])
ORDER BY
task_date, id
LIMIT 20;
[посмотреть на explain.tensor.ru]
Немного грустно — мы заказывали всего 20 записей, а Index Scan вернул нам 960 строк, которые потом еще и сортировать пришлось… А давайте попробуем читать поменьше.
unnest + ARRAY
Первое соображение, которое нам поможет — если нам надо всего 20 отсортированных записей, то достаточно читать не более 20 отсортированных в том же порядке по каждому ключу. Благо, подходящий индекс (owner_id, task_date, id) у нас есть.
Воспользуемся тем же механизмом извлечения и «разворота в столбцы» целостной записи таблицы, что и в прошлой статье. А также применим свертку в массив с помощью функции ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 — ограничиваем тут…
)) r
FROM
unnest(‘{1,2,4,8,16,32,64,128,256,512}’::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; — … и тут – тоже
[посмотреть на explain.tensor.ru]
О, уже намного лучше! На 40% быстрее, и в 4.5 раза меньше данных пришлось читать.
Материализация записей таблиц через CTE
Обращу внимание, что в некоторых случаях попытка сразу работать с полями записи после ее поиска в подзапросе, без «оборачивания» в CTE может приводить к «умножению» InitPlan пропорционально количеству этих самых полей:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);
Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4″
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
Одна и та же запись «поискалась» 4 раза… Вплоть до PostgreSQL 11 такое поведение встречается регулярно, и решением является «оборачивание» в CTE, что является безусловной границей для оптимизатора в этих версиях.
Рекурсивный аккумулятор
В предыдущем варианте суммарно мы прочитали 200 строк ради нужных 20. Уже не 960, но еще меньше — можно?
Давайте попробуем воспользоваться знанием, что нам надо всего 20 записей. То есть будем итерировать вычитку данных только до достижения нужного нам количества.
Шаг 1: стартовый список
Очевидно, что наш «целевой» список из 20 записей должен начинаться с «первых» записей по одному из наших owner_id-ключей. Поэтому сначала найдем такие «самые первые» по каждому из ключей и занесем в список, отсортировав его в порядке, который хотим — (task_date, id).
Шаг 2: находим «следующие» записи
Теперь, если мы возьмем из нашего списка первую запись и начнем «шагать» дальше по индексу с сохранением owner_id-ключа, то все найденные записи — как раз следующие в результирующей выборке. Конечно, только пока мы не пересечем прикладной ключ второй записи в списке.
Если получилось, что мы вторую запись «пересекли», то последняя прочитанная запись должна быть добавлена в список вместо первой (с тем же owner_id), после чего список снова пересортировываем.
То есть у нас все время получается, что в списке есть не более одной записи по каждому из ключей (если записи кончились, а мы не «пересекли», то из списка первая запись просто пропадет и ничего не добавится), причем они всегда отсортированы в порядке возрастания прикладного ключа (task_date, id).
Шаг 3: фильтруем и «разворачиваем» записи
В части строк нашей рекурсивной выборки некоторые записи rv дублируются — сначала мы находим такие как «пересекающую границу 2-й записи списка», а потом подставляем как 1-ю из списка. Так вот первое появление надо отфильтровать.
Страшный итоговый запрос
— #1 : заносим в список “первые” записи по каждому из ключей набора
WITH wrap AS ( — “материализуем” record’ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest(‘{1,2,4,8,16,32,64,128,256,512}’::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list — сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
— #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
— если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] — убираем ее из списка
— если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list — просто протягиваем тот же список без модификаций
— если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
— просто возвращаем пустой список
‘{}’
— пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), ‘{}’)
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( — “материализуем” record
SELECT
CASE
— если все-таки “перешагнули” через 2-ю запись
WHEN NOT T.not_cross
— то нужная запись – первая из спписка
THEN T.list[1]
ELSE ( — если не пересекли, то ключ остался как в предыдущей записи – отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
— если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE — ничего не нашли или “перешагнули”
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND — ограничиваем тут количество
T.list IS DISTINCT FROM ‘{}’ — или пока список не кончился
)
— #3 : “разворачиваем” записи – порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; — берем только “непересекающие” записи
[посмотреть на explain.tensor.ru]
Таким образом, мы обменяли 50% чтений данных на 20% времени выполнения. То есть если у вас есть причины полагать, что чтение может быть долгим (например, данные зачастую не в кэше, и приходится за ними ходить на диск), то таким способом можно зависеть от чтения меньше.
В любом случае, время выполнения получилось лучше, чем в «наивном» первом варианте. Но каким из этих 3 вариантов пользоваться — выбирать вам.
Источник